PDC 2020 is the 2020 edition of the Process Discovery Contest, and it consists of two contests: An automated contest followed by a manual contest.
Automated contest
 The aim for the automated contest is to show the current state of the art in the discovery algorithms. For this reason, one should submit a working implementation of the algorithm. To make this a bit easier, we have implemented 11 example discovery algorithms. These example algorithms do not participate in the contest, they only showcase how it can be done and what possible results are. If the authors of an example discovery algorithm want to compete with it, they should submit it.
The aim for the automated contest is to show the current state of the art in the discovery algorithms. For this reason, one should submit a working implementation of the algorithm. To make this a bit easier, we have implemented 11 example discovery algorithms. These example algorithms do not participate in the contest, they only showcase how it can be done and what possible results are. If the authors of an example discovery algorithm want to compete with it, they should submit it.
Manual contest
 The aim for the manual contest is to show the gap (if any) that exists between the results of the discovery algorithm and the results obtained by, say, humans. Of course, this also allows for fine-tuning the parameters of your discovery algorithm to the log at hand, which is not possible in the automated contest. As such, this may provide directions for future research.
The aim for the manual contest is to show the gap (if any) that exists between the results of the discovery algorithm and the results obtained by, say, humans. Of course, this also allows for fine-tuning the parameters of your discovery algorithm to the log at hand, which is not possible in the automated contest. As such, this may provide directions for future research.
Download the ZIP archive containing the logs for the manual contest. The file “pdc_2020_1211111_discover.xes” is the training log (from which you need to discover a model) and the file “pdc_2020_1211111_classify.xes” is the test log (which you need to classify using your discovered model). The resulting classified test log can be sent to process.discovery.contest@gmail.com.
When and how to submit?
Please let us know by an email to process.discovery.contest@gmail.com that you want to submit. We will then provide you with a link where you can upload your submission. Please see also the respective pages for both the automated and manual contest for details and when and how to submit.
Data set
 For the automated contest, we generated a data set containing 192 logs.
For the automated contest, we generated a data set containing 192 logs.
These logs are not disclosed for the automated contest.
After the automated contest has run, we disclose the most complex log for the manual contest. The manual contest will use only this most complex log.
Winners
The winner for the automated contest is the submission with the highest average F-score over all 192 logs. The winner for the manual contest is the submission with the highest F-score for the most complex log. In case of a tie, the earlier submission wins.
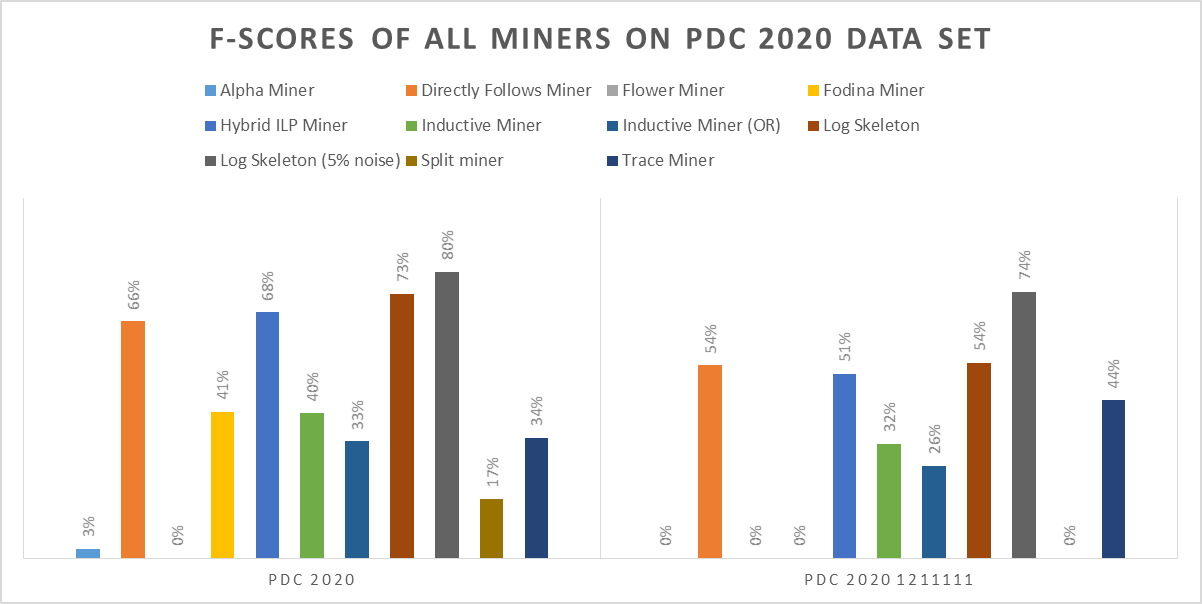
This graph shows the F-score values for the 11 example discovery algorithms over all 192 test logs (left, for the automated contest) and over only the most complex test log (right, for the manual contest).
Prizes
The winner teams in both categories will be selected by a jury and invited to present the results at the conference. They will also receive a certificate, and a small token of appreciation.
Results
The automated contest has been won by Sander Leemans with his submission called the Directly Follows Model Miner. Congratulations to Sander!
Important dates
- August 17: Deadline for the automated contest
- August 18: Disclosure of the most complex training and test logs
- Download the ZIP archive containing these logs for the manual contest. The file “pdc_2020_121111_discover.xes” is the training log (from which you need to discover a model) and the file “pdc_2020_1211111_classify.xes” is the test log (which you need to classify using your discovered model). The resulting classified test log can be sent to process.discovery.contest@gmail.com.
- August 31: Deadline for the manual contest
Organizers
- Josep Carmona, Universitat Politècnica de Catalunya (UPC), Spain
- Benoît Depaire, Hasselt University, Belgium.
- Eric Verbeek, Eindhoven University of Technology, The Netherlands
Any questions related to the contest can be directed to the organizers via process.discovery.contest@gmail.com.